The Hidden Bottleneck in AI-Driven Drug Discovery
The real challenge in AI-drive drug discovery is the broken data infrastructure.
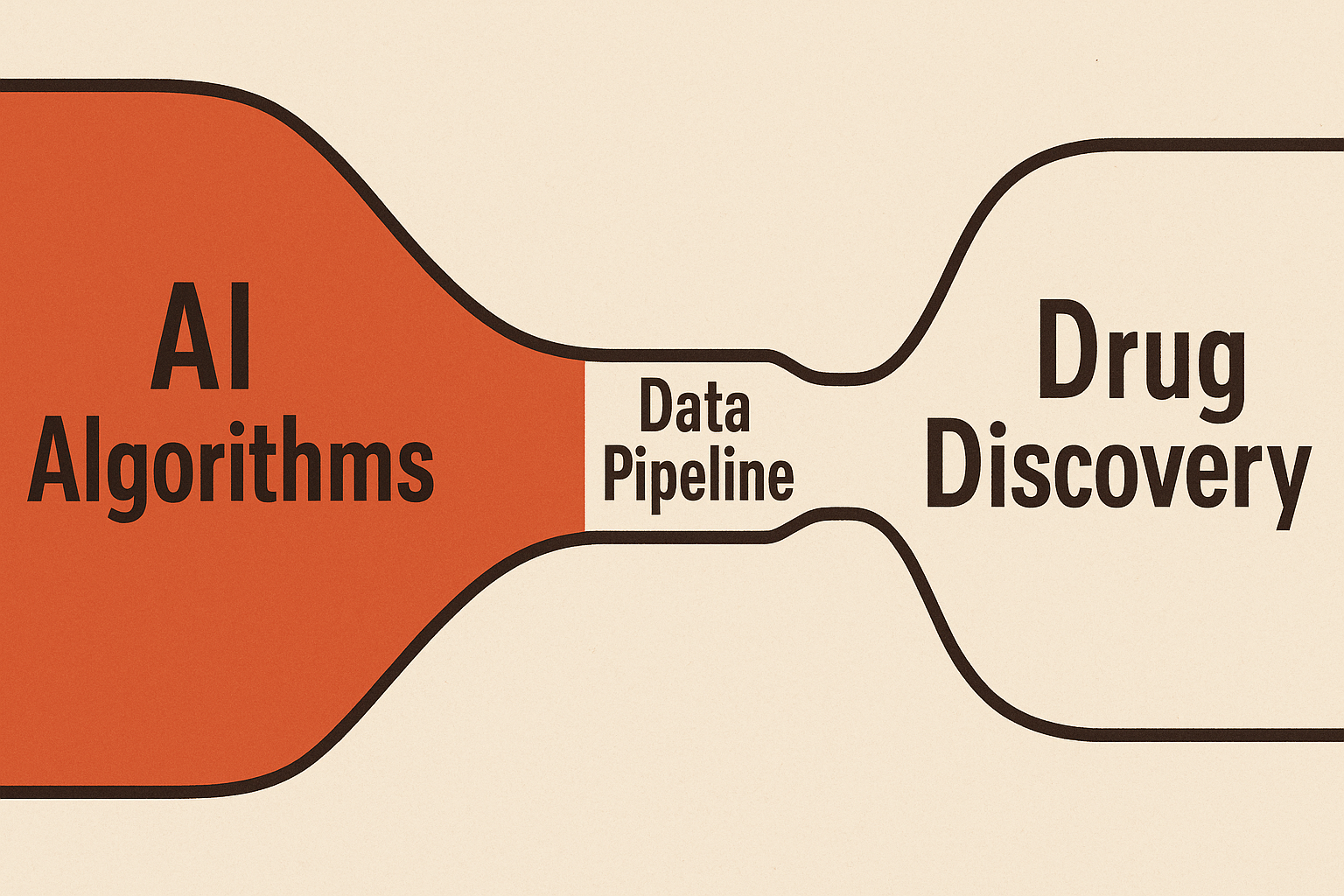
The real challenge in AI-drive drug discovery is the broken data infrastructure.

Why Biotech Needs Both (But Hires Only One)
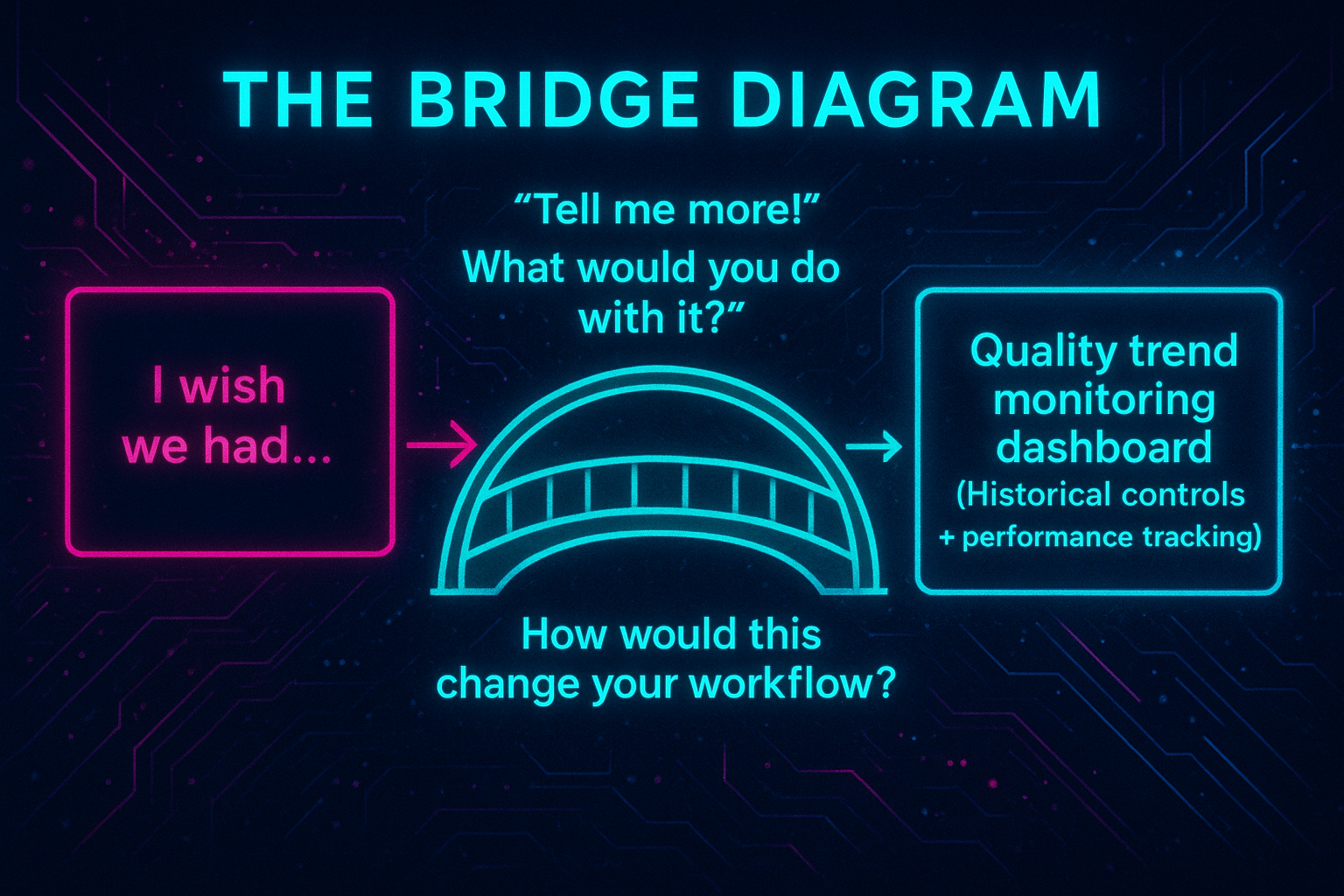
The difference between requirements and success criteria

Avoid the common data pitfalls that slow down growing biotech companies.
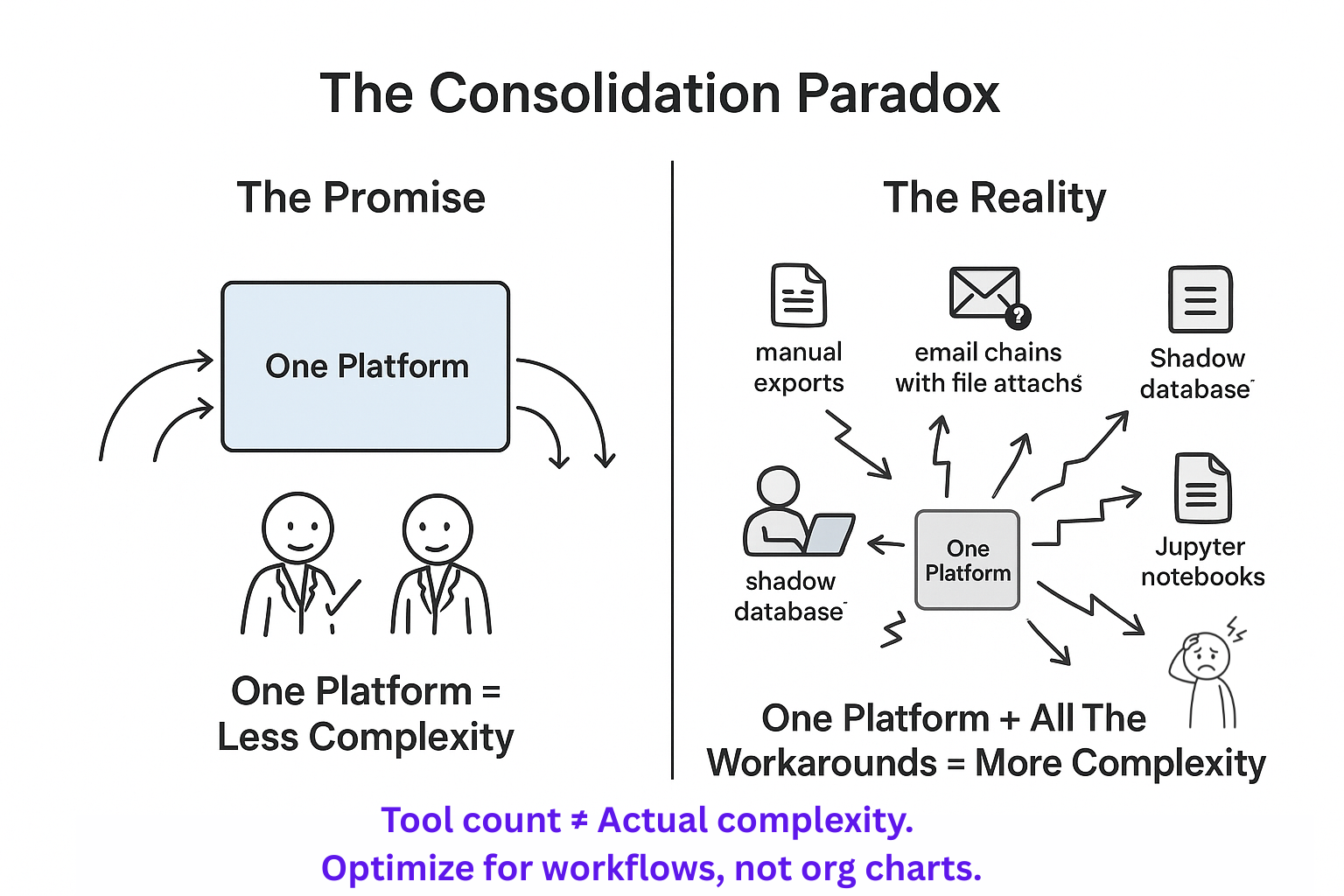
Why Fewer Tools Often Means More Complexity